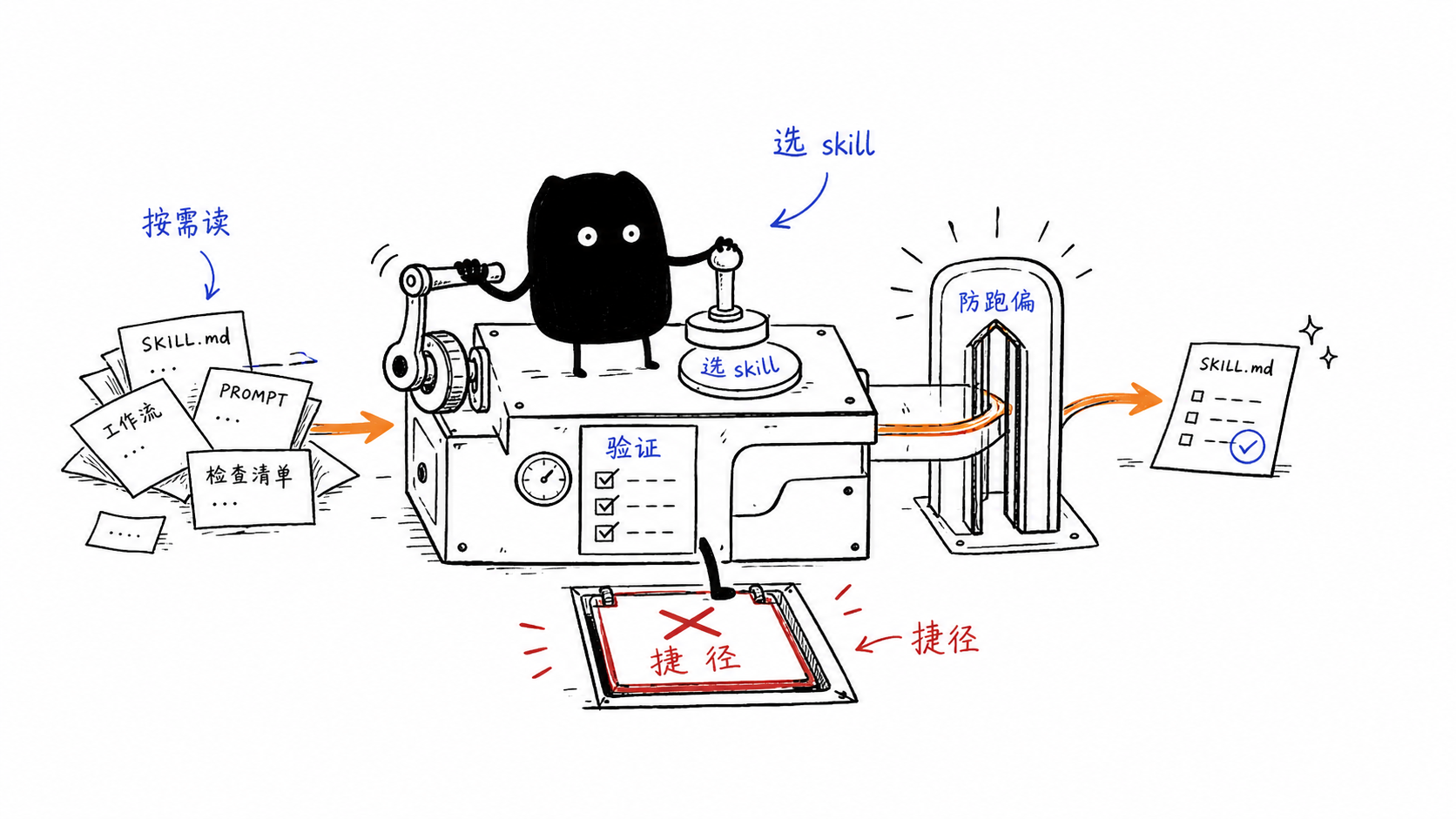
对 obra/superpowers v5.1.0 的源码走读。重点不是”装了它能干什么”,而是”它怎么让一个 LLM agent 真的按 skill 走、不偷懒、不偏题”。
背景
Claude Code、Codex CLI、Cursor、Copilot CLI、Gemini CLI 这一波 agent CLI 都引入了 plugin / skill 概念:一份 Markdown 描述某个工作流,模型在合适时机被自动唤起去读它。
但 skill 系统真正的工程难题不是”怎么写一份 Markdown”,而是:
- skill 怎么组织才不污染上下文窗口?
- 怎么保证模型在该用 skill 时真的用了,而不是凭印象跳过?
- 怎么让 skill 持续有效,而不是写完就过期?
- 模型在压力(赶时间、用户催促、感觉”这次简单”)下会偷懒,怎么防?
obra/superpowers 是目前我读过对这四个问题回答得最完整的开源 skill 库。它包含 14 个 skill(TDD、systematic-debugging、brainstorming、writing-skills 等),并把元方法论显式写在代码里。本文按”组织 → 唤起 → 维持有效性 → 防偏离”四层拆解。
一、目录组织
superpowers/5.1.0/├── .claude-plugin/plugin.json # CC 插件描述├── .codex-plugin/ .cursor-plugin/ # 其他平台适配├── hooks/│ ├── hooks.json # 注册 SessionStart hook│ ├── run-hook.cmd # 跨平台 polyglot 启动器│ └── session-start # bash 实现,注入元 skill├── .in_use/<pid> # 运行中会话锁文件├── skills/│ ├── using-superpowers/ # 元 skill:教模型怎么用 skill│ ├── writing-skills/ # 元 skill:教模型怎么写 skill│ ├── brainstorming/│ ├── test-driven-development/│ ├── systematic-debugging/│ └── ... (共 14 个)├── tests/│ ├── skill-triggering/ # "自然 prompt 能否触发 skill"│ ├── explicit-skill-requests/ # "显式要求时能否触发"│ └── subagent-driven-dev/ # 端到端流程测试└── AGENTS.md → CLAUDE.md (软链)每个 skill 一个目录,固定结构:
SKILL.md(必有,YAML frontmatter 含name和description)- 可选的 reference 文件(子文档、
prompts/、示例代码、脚本)
skill 体积分布(行数):
| skill | 行数 |
|---|---|
| executing-plans | 70 |
| using-superpowers | 117 |
| verification-before-completion | 139 |
| writing-plans | 152 |
| brainstorming | 164 |
| test-driven-development | 371 |
| writing-skills | 655 + 5 个附件 |
14 个 skill 总计 3207 行。
关键设计:SKILL.md 是目录索引,重的 reference 按需 @import。这呼应 anthropic 在 writing-skills/anthropic-best-practices.md 里强调的:“context window 是公共资源——元数据(name+description)开会话就预加载,正文按需读。“
二、唤起机制(三层)
第 1 层:SessionStart hook 强制注入
hooks/hooks.json:
{ "hooks": { "SessionStart": [ { "matcher": "startup|clear|compact", "hooks": [ { "type": "command", "command": "${CLAUDE_PLUGIN_ROOT}/hooks/run-hook.cmd session-start" } ] } ] }}hooks/session-start 干的事:
- 读取
skills/using-superpowers/SKILL.md全文 - 用 bash 参数替换转义成 JSON 字符串
- 包进
<EXTREMELY_IMPORTANT>标签 - 按当前平台输出不同字段:
- Cursor →
additional_context - Claude Code →
hookSpecificOutput.additionalContext - Copilot CLI → 顶层
additionalContext
- Cursor →
核心设计:using-superpowers skill 不是按需加载,而是每次开会话 / clear / compact 都强制塞进 system context。这等于绕过模型自主判断,硬启动”主动找 skill”的元意识。
第 2 层:Skill 工具按需调用
其他 13 个 skill 通过 Skill 工具调用,描述里都有强触发关键词:
# test-driven-developmentdescription: Use when implementing any feature or bugfix, before writing implementation code
# systematic-debuggingdescription: Use when encountering any bug, test failure, or unexpected behavior, before proposing fixes
# brainstormingdescription: You MUST use this before any creative work - creating features, building components, adding functionality, or modifying behavior.description 字段就是触发器。anthropic-best-practices.md 明确要求两要素:(1) 什么时候用 (2) 解决什么问题。
第 3 层:.in_use/<pid> 锁文件
{ "pid": 22869, "procStart": "Thu Jun 4 07:28:33 2026" }每个运行中会话留一份 PID 锁,给后续机制(更新检测、并发 skill 使用统计等)做依据。
三、怎么保持 skill 持续有效
writing-skills 是一个对自身适用的元 skill——它明说:“Writing skills IS TDD applied to process documentation.”
整套迭代方法论:
| TDD 阶段 | Skill 测试映射 | 实际动作 |
|---|---|---|
| RED | Baseline 测试 | 不装 skill,跑 prompt,观察 agent 失败 |
| Verify RED | 抓 rationalization | 逐字记录 agent 编了什么理由 |
| GREEN | 写 skill | 针对具体失败模式写文档 |
| Verify GREEN | 加压测试 | 装上 skill 重跑,验证合规 |
| REFACTOR | 堵漏洞 | 找新合理化借口,加反制 |
| Stay GREEN | 回归测试 | 再跑一遍确保不退化 |
具体跑这套循环的脚手架就在 tests/skill-triggering/:
claude -p "$PROMPT" --plugin-dir "$PLUGIN_DIR" \ --output-format stream-json > "$LOG_FILE"
# 在 stream-json 里 grep "name":"Skill" + "skill":"<name>"# 命中 → PASS,没命中 → FAIL测试 prompt 用的是自然语言(prompts/test-driven-development.txt 等),不显式提 skill 名——验证模型能否仅凭 description 触发对应 skill。这是真正意义上的”skill 库 CI”。
四、怎么防偏离目标(最值得抄的部分)
这是 superpowers 最有研究价值的设计。它明确建立在 Cialdini 七大说服原则 + Meincke et al. (2025) N=28,000 LLM 服从性实验(合规率从 33% 提升到 72%)之上。persuasion-principles.md 把策略写明白:
A. 修辞武器
| 原则 | 实现手段 | 例子 |
|---|---|---|
| Authority(权威) | YOU MUST / Never / No exceptions | ”Write code before test? Delete it. Start over.” |
| Commitment(承诺) | 强制 announce + TodoWrite 跟踪 | ”When you find a skill, you MUST announce: ‘I’m using [X]‘“ |
| Scarcity(紧迫) | IMMEDIATELY / Before proceeding | ”After completing a task, IMMEDIATELY request code review” |
| Social Proof(从众) | “Every time” / “X without Y = failure" | "Checklists without TodoWrite = steps get skipped. Every time.” |
| Unity(同盟) | “we’re colleagues” | 反 sycophancy |
| ❌ Liking | 明确禁用 | ”Conflicts with honest feedback culture. Creates sycophancy.” |
| ❌ Reciprocity | 慎用 | ”Almost always (other principles more effective)” |
按 skill 类型组合:
- Discipline-enforcing(TDD / debugging):Authority + Commitment + Social Proof
- Guidance:Moderate Authority + Unity
- Reference:Clarity only,零说服
B. 三种结构化反偏离装置
1. Iron Law(铁律):把目标压成不可越线的一句话
TDD skill:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRSTDebugging skill:
NO FIXES WITHOUT ROOT CAUSE INVESTIGATION FIRST不是建议、不是流程图、就一行——降低模型在压力下”重新解释规则”的可能性。
2. <HARD-GATE> / <EXTREMELY-IMPORTANT> 标签
<HARD-GATE> Do NOT invoke any implementation skill, write any code, scaffold any project, or take any implementation action until you have presented a design and the user has approved it. This applies to EVERY project regardless of perceived simplicity.</HARD-GATE>物理上”卡住”流程的下一步。配合 using-superpowers 里的 1% 规则——“哪怕 1% 可能适用也必须调用 skill”——形成双重锁。
3. Rationalization Table(合理化对照表):预编译反借口词典
每个 discipline skill 都有一张,给模型还没说出口的偷懒念头当头一棒。TDD 那张节选:
| Excuse | Reality |
|---|---|
| ”Too simple to test” | Simple code breaks. Test takes 30 seconds. |
| ”I’ll test after” | Tests passing immediately prove nothing. |
| ”Already manually tested” | Ad-hoc ≠ systematic. |
| ”Deleting X hours is wasteful” | Sunk cost fallacy. |
| ”TDD will slow me down” | TDD faster than debugging. |
| ”This is different because…” | (默认列入 red flag) |
using-superpowers 里还有一张元层级红旗表(“This is just a simple question” / “I remember this skill” 等),专门拦截”跳过 skill 检查”的念头。
C. 强制承诺协议
using-superpowers 的流程图明确规定:调用 skill 后必须 announce。
Invoke Skill tool │ ▼Announce: "Using [skill] to [purpose]" │ ▼Has checklist? ──yes──▶ TodoWrite per item │ no ▼Follow skill exactly承诺一旦说出口,模型会在后续 token 里维持一致性(Cialdini commitment principle 在 LLM 上有效)。TodoWrite 把流程物化为可见 todo,进一步抗遗忘——同时给用户提供监督手柄。
五、整体架构
SessionStart hook │ ▼ ┌────────────────────────┐ │ using-superpowers 注入 │ ← 元 skill:教模型"找并用 skill" │ (强制、绕开模型判断) │ └────────────────────────┘ │ User message received │ ▼ ┌────────────────────────┐ │ 1% 规则 + 红旗表 │ ← 强制 check skill │ Process > Implementation│ └────────────────────────┘ │ ▼ ┌──────────────┐ │ Skill tool │ ──→ 加载具体 SKILL.md └──────────────┘ │ ▼ ┌─────────────────────────────────────┐ │ skill 自带的防偏离三件套: │ │ - Iron Law(单行铁律) │ │ - HARD-GATE(流程闸门) │ │ - Rationalization Table(反借口) │ │ + Announce + TodoWrite 锁定承诺 │ └─────────────────────────────────────┘ │ ▼ tests/skill-triggering 回归测试 writing-skills 持续 TDD 迭代六、几个核心洞察
- 元 skill 自启动——不靠模型记得用,而是 hook 物理注入。
- 说服心理学工程化——基于学术研究有意识地组合 Cialdini 原则,并显式禁用 Liking / Reciprocity(反 sycophancy)。
- TDD 应用于文档——
writing-skills把 skill 当代码来 RED-GREEN-REFACTOR 测试驱动。 - 预编译反合理化——把模型最常用的偷懒借口提前写进 skill,断绝其在压力下自我说服的路径。
- Context 经济——skill metadata 永驻、正文按需,避免污染上下文窗口。
七、取舍
- 优点:可读性强、机制透明、跨 agent 平台(CC / Cursor / Codex / Copilot / Gemini)。
- 代价:SessionStart 强制注入约 117 行内容,每次开会话都吃 token;Iron Law 风格对 flexible 场景(探索性、创意性任务)可能过于刚性。
- 适用边界:discipline-enforcing 类(TDD / debug / review)受益最大;纯 reference 类 skill 用这套修辞反而显啰嗦。
八、能直接抄到自己项目的模式
- 在项目
AGENTS.md/CLAUDE.md里加一段 Iron Law 风格的硬约束。 - 在跨仓改动、commit、API 修改前加
<HARD-GATE>块,强制模型 announce 自己要做什么。 - 把项目反复踩过的坑写成一张 Rationalization Table(例如 “这个改动很小不用看后端” → “client/server schema 漂移就是这么发生的”)。
- 给关键流程写”红旗思考”清单,列出模型常见的偷懒借口,提前驳斥。
参考
- obra/superpowers v5.1.0
skills/writing-skills/anthropic-best-practices.mdskills/writing-skills/persuasion-principles.md- Cialdini, R. B. (2021). Influence: The Psychology of Persuasion (New and Expanded). Harper Business.
- Meincke, L., Shapiro, D., Duckworth, A. L., Mollick, E., Mollick, L., & Cialdini, R. (2025). Call Me A Jerk: Persuading AI to Comply with Objectionable Requests. University of Pennsylvania. (N=28,000,合规率 33% → 72%)
Comments
Quiet notes for this article.